Folks negotiating a new climate treaty in Paris ought to have a look at this picture, which shows the abject failure of the computer models they are using as the basis for climate policy:
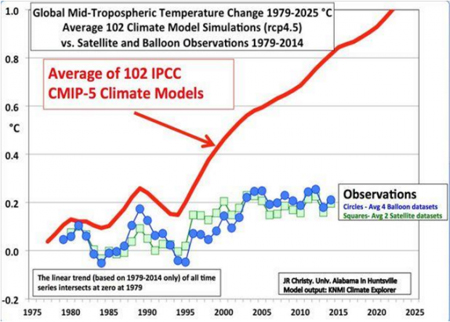
It was presented last May to the Natural Resources Committee of the U.S. House of Representatives by University of Alabama's John Christy.
It isn't the usual comparison between surface temperatures and climate forecasts. Instead, it shows the forecast and observed temperature of the middle troposphere. The troposphere is where the world's weather action is, from the surface on up to around 45,000 feet (depending upon latitude and season).
The red line is the average mid-tropospheric temperature in the 102 climate models used by the UN in its latest compendium of published scientific opinions on climate change. It's smoothed out by using running five-year averages, not a bad way to get rid of the year-to-year noise in annual data.
The green squares are the average of the two satellite-sensed temperature histories for the mid-troposphere. The blue dots are a completely independent measure of that temperature, which is the average of the four commonly-cited analyses of global weather balloon data. These are taken twice a day with extremely accurate sensors. Both of these datasets were subject to the same smoothing as the model predictions.
In his congressional testimony, Christy really didn’t have time to explain the larger significance of his finding, which is that it sends the forecasts into the recycling bin.
Rain and snow are principally dependent upon the temperature difference between the surface and the mid-troposphere. When there’s little difference, the air is said to be “stable,” meaning the vertical movement that’s required to form a cloud is inhibited. Think thunderheads on a hot day. When the difference is large, explosive storms develop.
Getting this difference wrong mean getting rainfall wrong, which means subsequent forecasts of surface temperature, including daily highs and lows are also wrong. A moist surface warms much more slowly than a dry one (been to the desert recently?). Similarly, wet surfaces cool more slowly at night. If the models somehow got these correct, it would either by dumb luck or with some sort of adjustment (known in freshman chemistry as “fudging” to get the right answer).
Indeed, the failure in the mid-troposphere is one of the major reasons that the models also are having so much trouble with the surface temperature forecast.
Speaking of those temperatures, they’re a bit slipperier than the mid-tropospheric ones. The laboratories responsible for the three principal versions of surface temperature history keep changing them, much more frequently than the satellite or the weather balloon data are reconfigured.
When we examined the surface temperature behavior in a presentation to the American Geophysical Union last fall, we used the one from the Climate Research Unit at the University of East Anglia because it provides the closest match to the mid-tropospheric satellite data, compared to the other two histories, from NASA and the Department of Commerce.
Our results made the models look very bad. Since then, the CRU revised history by warming up recent years, so if we run our experiment now the models merely look bad.
It’s mind-boggling that our leaders continue to cling to these failed models as the Paris summit stumbles to its predictable conclusion, which will be a lukewarm, unenforceable agreement, perhaps fitting for an atmosphere that is similarly lukewarming.
About the Author
