Mathew Kelly and I provided a new ranking of state educational systems that was published as a Cato Policy Analysis in November of 2018. Our goal was to provide a ranking that did not treat all states as if their student populations were identical, unlike traditional state rankings. Instead, students of a particular ethnic group were compared across states and the state ranked based on its average of the group rankings. These rankings were further extended to provide evidence of how much student learning ‘bang’ states were getting for their expenditures (‘bucks’). Finally, we ran some regressions of state performance, measured in this manner, to see which factors appeared to be related to successful educational outcomes.
Rutgers University professor Bruce D. Baker responded to this work in a review published by the National Education Policy Center.[1] While scholars often feel gratified to see their work discussed by other academics, this gratification can turn to annoyance if the discussion becomes unreasonably hostile or unprofessional, especially when the discussion is filled with errors, as Baker’s discussion is. Fortunately, Baker’s commentary, though replete with nasty slights, mostly deals with questions that were already answered in our report, making my response easier.
Before responding to Baker’s critiques, however, some housekeeping items are in order. Baker reports several times that our study was published by the Reason Foundation as a “policy brief”. This is incorrect. We did publish a short article in the November 2018 issue of the monthly Reason Magazine which summarizes our results and methods and was written for a lay audience.[2] At the end of that Reason article we steered readers to the more complete, academic style article published as a Cato Policy Analysis on November 13th of that year, and Baker does reference this Cato report in his first footnote.[3] Nevertheless, he mislabels this Cato Policy Analysis as a Reason Policy Brief over a dozen times throughout his text. He refers over thirty times to our “reports” in the plural when we have only one academic style published report, the Cato Policy Analysis, which obviously replaces the prior working paper that we had uploaded on a working paper website.[4] Baker should know that academics routinely improve working papers into final published articles and that references should be made to the published article. This ‘housekeeping’ error is a minor issue in the larger scheme of things, but at a fundamental level it reveals a sloppiness that permeates Baker’s overall analysis.
All of my discussion here is based on the Cato Policy Analysis, which is the complete finalized published work, not a short magazine article or an unpublished working paper.
Baker’s criticisms boil down to four main points. First, he claims that we inappropriately gave equal weight to different racial groups in constructing our quality ranking. Second, Baker feels that our regression results are wrong and that we overstate the decisiveness of our regression results. Third, he argues that additional variables ought to have been included in the analysis, particularly measures related to the income in student households. Fourth, he takes issue with our cost-of-living adjustment of education expenditures.
Each of these criticisms either was discussed and resolved in our paper, or is invalid, as I now will show.
Equal weighting of ethnic groups
Baker finds our equal weighting of the student scores from the four ethnic groups to be the most important problem in our report. He states “First, perhaps most troubling is the reports’ construction of the ‘quality’ measure [student scores]” (p10). One of the key improvements of our state rankings over those used in Education Week or US News and World Report was that we compared the performance of white students in one state against the performance of white students in other states, black students against other states’ black students, and so on, for four ethnic groups. We take the average these four comparisons to create our “quality” rankings. Baker calls this “bizarre.”
Baker illustrates why he believes our equal weighting must cause important errors in our results, using Vermont and Wyoming as examples:
The approach [of Liebowitz and Kelly] inappropriately places equal weight in states like Vermont or Wyoming on students comprising 1 to 2% of the population as the other 98 to 99%. [p5]
For example, while Vermont’s scores for white children generally exceed national averages, the state’s very small black population (<2%) underperforms, even compared to black children nationally. Weighting them the same (rather than 98/2) substantially lowers Vermont’s “quality” measure, but may merely reflect the instability of the scores for such a small sample or some other unique attribute of the small, tested sample of black children in Vermont. [p7]
We could have assigned various weightings of groups to calculate state score averages. We could have weighted each group’s score on each exam in proportion with that group’s share of the takers of that test (actually we did this in our study and reported how little it changed our rankings, as described in the next paragraph). We could have weighted minority groups by their share of the national or state population. However, the criteria for determining these weightings would ultimately have been somewhat arbitrary. Our decision to give extra weights to minority scores, however, was a conscious decision on our part. For one thing, we wanted to make a state’s measure of success in educating its minority students an important factor in our ratings. We wanted to err on the side of overemphasizing the performance of a state’s minority students in the rankings. Baker apparently disagrees. But there is a more fundamental problem with Baker’s assertion.
The important fact that invalidates everything that Baker says on the subject of our weighting of ethnic groups is that we specifically examined whether our choice of equal weights would have a consequential impact on our results. As we explained in our report, we ran a version of our study using the very weighting scheme that Baker says we should have performed but which he accuses us of not performing.
Here is what we said in our report:
One might argue that we should use an average weighted by the share of students [in each group], but we choose to give each group equal importance. If we had used population weights, the rankings would not have changed very much because the correlation between the two sets of scores is 0.86, and four of the top-five and four of the bottom-five states remain the same. [fn 19]
This statement makes clear that we did run the rankings with the weights that Baker says we should have used, but that the results were largely the same as our main results. Clearly, we are aware of this issue, yet Baker tells his readers that we ignored it.
But I want to return briefly to Baker’s illustration of our so-called “deceptive” (p10) methods. Go back to the above quotes from Baker about Vermont and Wyoming in order to follow along.
First, Vermont’s white students were not above the average of the other states’ white students, as Baker claims, but were below the average of other states’ white students in four of the six exams used in the analysis and were a non-trivial three tenths of a standard deviation below when the six exams are averaged. Second, contrary to Baker’s assertions, Vermont’s scores were not lowered because of an overemphasis on the scores of Vermont’s “underperforming” black students. In fact, Vermont’s black students were above the average of black students in other states.[5] Third, contrary to Baker’s assertions, our calculations of Vermont’s and Wyoming’s scores were much less influenced by their small minority populations than Baker claims. The NAEP dataset that we use does not report a group’s scores on a test when the number of students in that group is too small for a reliable sample to be chosen (as was the case for Vermont’s Hispanic and Asian students and Wyoming’s black and Asian students). When a group’s scores are not included, which is common for groups with very small shares, that group cannot influence our calculation for the state.
Given all his errors, I find it ironic for Baker to describe our work as being “deeply problematic” (p11), “rather meaningless if not outright deceptive” (p8), and “illogical to merely wanting of methodological rigor” (p5).
His Misunderstanding of His and Our Regression Results
Baker is unhappy with our regression results (“the final straw”).
The first of our regression results that offends him has to do with the impact of state expenditure per student on student performance, which we had concluded was essentially nonexistent using the cost of living (COL) adjusted data (although we also found it to be positive up to expenditure levels of $18.5k using the less informative non-COL data). We interpreted this to mean not that spending didn’t matter, but that “most states have reached a sufficient level of spending such that additional spending does not appear to be related to achievement as measured by these test scores” (p12).
In response, Baker claims to present regression evidence using his own data that shows a greater positive impact of spending (expenditure) per student on student performance.
As he describes his method and results:
Using a biennial, symmetrical panel of data from 2000 to 2015, applying robust standard errors, Table 2 shows that the coefficients for spending (expressed in thousands of dollars per pupil, adjusted for wage variation, scale and population density) are positive in all cases, and statistically significant for Grade 4 Reading. P14
I reproduce the regression results for his spending variables (curexp000s and curexp000s_sq) taken from the first two rows of his Table 2 in the table titled “From Baker’s Table 2.”
|
From Baker’s Table 2 |
Math 8 |
Math 4 |
Reading 8 |
Reading 4 |
||||
|
|
coef |
R.S.E. |
coef |
R.S.E. |
coef |
R.S.E. |
coef |
R.S.E. |
|
curexp000s |
0.288 |
0.252 |
0.347 |
0.25 |
0.307 |
0.228 |
0.386* |
0.202 |
|
curexp000s_sq |
-0.014 |
0.01 |
-0.018* |
0.01 |
-0.015* |
0.009 |
-0.019** |
0.008 |
Baker’s claim that “that the coefficients for spending…are positive in all cases” is incorrect. In all cases the linear term is positive, but also in all cases the squared (quadratic) term (curexp000s_sq) is negative. In determining the impact of spending on student test performance it is the joint impact of the linear and squared spending variables that determines the overall impact of spending on student performance. This should be an elementary concept to any researcher claiming to be able to judge our analysis and it is unfortunate that Baker apparently does not understand how quadratic terms are interpreted. Yet he refers to our work as “inept and intentionally ignorant” (p10).
Quadratic relationships such as these, when the linear term is positive and the squared term is negative, imply an inverted U‑shaped curve. The economic interpretation here would be that spending has an initial positive impact on student performance but that after some level of spending (diminishing returns) the impact on performance declines. Using Baker’s own results, when I solve for the point where spending no longer has a positive impact on learning, it is at a level of $10,000 per student, a value that a majority of states currently surpass.[6]
Thus, his results indicate that most states are likely to have reached the point where additional expenditures do not have a positive impact on student performance. And because the positive linear relationship between spending and student learning is statistically insignificant for three of the four student tests he examines, we cannot have confidence that any particular relationship between spending and student performance exists in those cases.[7] Thus, his regression results support a view that additional spending has no positive impact on performance, although Baker seems not to understand this.
Next, Baker objects to our finding that union strength weakens student performance. He bases his claim on his belief that unions increase expenditure/student and teacher/student ratios, and his belief (contrary to the implications of his Table 2 as we have just seen) that all three variables must increase student performance. Given that belief, he claims that all three variables will be collinear with each other and that this will distort our results. Econometricians refer to this as multicollinearity, and he is correct that it might distort our results for the union strength variable.
But we have econometric tools to help us determine whether multicollinearity is likely to cause problems. Removing the ‘collinear’ variables, such as teacher/student ratios or the expenditure per student variable(s), one at a time or in combination, hardly changes the union coefficient, contrary to his claim. Also, a popular tool for indicating the likelihood of collinearity is the “variance inflation factor,” or VIF which, for our union strength variable is only 1.44, well below the usual cutoff points indicating a high probability of multicollinearity.[8] Thus, Baker’s concern is just another example of a supposed problem that turns out not to be one.
Finally, Baker accuses us of making “bold conclusions” or excessively decisive claims about our results. This is in spite of our attempts to show scientific modesty while acknowledging our model’s limitations.
We have a section of our report where we discuss its limitation, unsurprisingly titled “Some Limitations.” We describe our econometric methodology as “rather simple” (p13). We report that our “data allow us to make a brief analysis of some factors that might be related to student performance in states” (p9). We point out that “regression analysis can show how variables are related to one another but cannot demonstrate whether there is causality between a pair of variables” (p11).
We even critique the process of trying to rank states:
the entire enterprise of ranking state-level systems is only a blunt instrument for judging school quality…Schools differ from district to district and within districts. We generally dislike the idea of painting the performance of all schools in a given state with the same brush. [p13]
We leave it to the reader to decide whether we were making grand claims that went far beyond what our data could imply.
Additional Controls
Baker heavily criticizes our choice to use only ethnicity measures to control for differences in populations and says that we needed to include other measures of socioeconomic status. He states:
The choice to ignore outright or brush aside income or poverty measures is inexcusable when state-level NAEP scale scores remain so highly related to income variation across states. [P.10, my emphasis]
We could have broken down the student population by other characteristics, such as income (proxied by reduced price lunches), language, or parental education. However, as we note in our report, this would make little difference to our results, would have added much greater complexity, and required the use of a non-public dataset. We knew that undertaking this more complex study would have led to largely the same results by having already examining a study similar to ours that included every control in the NAEP data. Footnote 4 in our report states:
“A 2015 report by Matthew M. Chingos, “Breaking the Curve,”…published by the Urban Institute, is a more complete discussion of the problems of aggregation and presents on a separate webpage updated rankings of states that are similar to ours…Chingos uses more controls than just ethnicity, but the extra controls have only minor effects on the [his] rankings.”
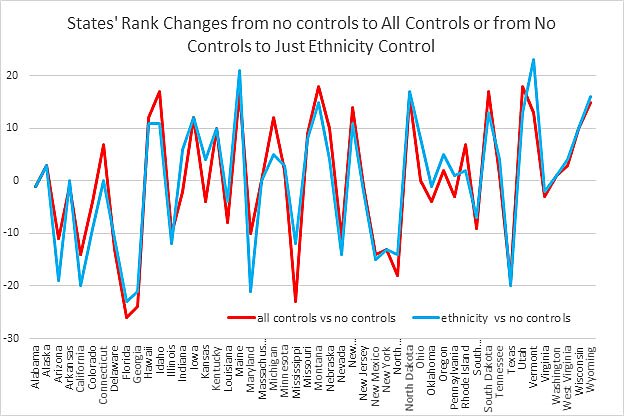
Chingos’ rankings of states[9] differed only slightly depending on whether only ethnicity controls were used (our method) or whether all available NAEP controls were used (age, race, English spoken at home, special education status, reduce price lunch, English learner status), as Baker suggests. The nearby chart reveals the similarity of results whether just ethnicity is used or whether the full set controls are used.
If the extra controls have a large impact, the blue and red lines would deviate greatly from each other. It is fairly obvious from the chart that ethnicity by itself picks up almost all of the effects that are to be had using all the controls, but for those not trusting their eyes, the correlations between rankings controlling for just ethnicity and rankings based on all the controls is 0.93. Based on these results, most of the heterogeneity that can be accounted for is captured by using just ethnicity, as we did in our rankings. A perusal of the Urban Institute rankings using all controls reveals that their results are quite similar to ours, although we were not aware of their rankings until after we had created ours (although we were obviously aware of them before our report was published).
Thus, Baker is incorrect to claim that our use of ethnicity alone to adjust our rankings will lead to numerous, serious, and inexcusable errors. That did not stop him from describing our results as “suspect, if not rubbish” (p15) and based on an “anemic evidentiary basis” (p8).
Baker also argues that we should further disaggregate students into specific nationalities, since not all Hispanics or Asians are alike. We agree, and we said so in our report.[10] But the NAEP testing data simply doesn’t allow for that fine-grained detail.
Cost of living
Baker’s final point concerns our cost-of-living (COL) adjustment of education expenditures. He states:
The per-pupil spending measure, adjusted only for regional cost of living, is equally insufficient. First, even when it comes to adjusting for regional cost variation, cost of living is not the appropriate or generally accepted measure. Rather, the National Center for Education Statistics has adopted a Comparable Wage Index approach developed by Professor Lori Taylor at Texas A&M, which remains publicly available at the district or state level. [p8]
We believe that the overall cost-of-living is the more appropriate way to adjust education expenditures since it more properly reflects the purchasing power of monies removed from taxpayers and also the purchasing power of teacher salaries. That being said, the cost-of-living index we used is just one among many such indices that could be used, each with pros and cons.
Nonetheless, either measure for comparing costs across states is likely to be similar and indeed the 2014 Taylor CWI (the most recent) has a correlation of 0.57 with the 2017 cost of living measure that we used.
But let’s cut to the chase here. As is the case throughout his criticism, Baker latches on to a potential flaw in our analysis and claims that the very possibility of a problem destroys the validity of our results without providing any evidence that the so-called flaws affect our results in any important way. The most direct test of his claim here is to simply compare our results to the results we would have generated had we used Taylor’s CWI values instead of the COL values that we used.
Guess what? The simple correlation between our COL rankings and the rankings generated using CWI is 0.92. The top five states in our report, using COL dollars spent, are Florida, Texas, Virginia, Arizona, and Georgia. The top five using CWI dollars are Texas, Florida, Virginia, Georgia and Arizona. The bottom five in our report, starting with the worst state, are West Virginia, Alabama, Maine, Alaska and Louisiana. The bottom five using CWI are Maine, Alaska, West Virginia, Alabama, and Vermont. Nine of these ten states are the same, with only minor variations in their order.
Using Baker’s preferred living cost adjustments leads to only a trivial change in results. Nevertheless, he refers to our approach as “deceptive, if not deceitful” (p10).
Conclusions
Baker’s review has little to recommend it. Our published article had already examined and taken care of his more reasonable concerns, although he seems not to have noticed. His other concerns are based on incorrect reasoning and factual inaccuracies. Although we made extensive changes in response to reviewers while we were finishing our article, I do not believe there is anything in Baker’s review that would improve our results in any serious manner.
In addition to his flawed analysis, Baker seems consumed with discrediting our results through innuendo and even direct claims of our dishonesty. He claims that we, for some unstated reason, did not want to see the District of Columbia do as well as it does on our rankings, ignoring the actual and more plausible reason that we wanted to check out the cause of a surprising result. Similarly, he insists that we wanted to show no linkage between spending and performance even though we reported that very result in an earlier version of our report before using COL adjusted data. He frequently asserts that our state rankings began with a preexisting preferred ranking and that we worked backward (“baked”) to create a methodology that would produce ranks that fit our priors. But we did not, nor could we if we wanted to, plan to find a methodology that would lead to a particular ranking of states. This is just nonsense.
Some of Baker’s other complaints are simply lazy. For instance, he claims on page 13 not to know whether our data is a panel or a cross-section (“It is unclear if more than a single year of data were used in their regression”) although back on his page 9 he had noted (correctly) that it was a cross-section (“point-in-time, cross-state regression”). It’s also unclear why he devotes a two-paragraph endnote (5) to our z‑score construction that does not actually say anything except to provide a whiff of innuendo.
Alternative weighting schemes, regression model specifications, additional controls, and cost-of-living adjustments can and should be discussed and tried, but Baker, when he is not making mistakes, proposes nothing new. Our method, as laid out in our Cato policy analysis, remains valid, and although it leads to a large improvement over previous state rankings, it is obviously not the final word. Perhaps Baker can shake off his ideological baggage and join us in creating better state rankings.
Notes
[1] Bruce D. Baker, “NEPC Review: Everything You Know About State Education Rankings is Wrong (Reason Foundation, November 2018) and Fixing the Currently Biased State K‑12 Education Rankings (University of Texas, September 2018),” National Education Policy Center, November 27, 2018, https://nepc.colorado.edu/thinktank/review-rankings.
[2] Stan J. Liebowitz and Matthew J. Kelly, “Everything You Know About State Education Rankings is Wrong,” Reason Magazine, November, 2018, https://reason.com/archives/2018/10/07/everything-you-know-about-stat.
[3] Stand J. Liebowitz and Matthew L. Kelly, “Fixing the Bias in Current State K–12 Education Rankings,” Cato Institute Policy Analysis no. 854, November 13, 2018, https://object.cato.org/sites/cato.org/files/pubs/pdf/pa_854.pdf.
[4] The Social Science Research Network, https://www.ssrn.com/en/.
[5] Vermont’s black students make up a small enough share that they were almost excluded from the NAEP data. But there were enough students for the NAEP to provide data for black fourth grade math scores, which were used in the analysis.
[6] His data cover years from 2000–2015. I presume that all dollar values are converted to 2015 dollars, although that is not clear from Baker’s report.
[7] The coefficients from those regressions also imply that expenditure per student decreases learning after about $10,000 per student, although we should not have confidence in those results.
[8] The lowest possible value for VIF is 1 and the cutoff points indicating possible trouble are normally thought to be 5 or 10.
[9] Matthew Chingos et al., “America’s Gradebook: How Does Your State Stack Up?,” Urban Institute, last modified September 28, 2018, http://apps.urban.org/features/naep/.
[10] We stated (p14): “Our rankings assume that students in each ethnic group are similar across states. Although this assumption may not always be correct, it is more realistic than the assumption made in other rankings that the entire student population is similar across states.”
